
Merge Request
Voir aussi Pull Request utilisé par GitHub.
Journaux liées à cette note :
Journal du mardi 06 mai 2025 à 14:49
Je gère actuellement un projet comprenant 8 Merge Requests empilées (Stacked PRs) en cours de review, s'étendant sur une période d'environ deux mois.
Au fur et à mesure que je continue à travailler sur ce projet, j'ai effectué à plusieurs reprises des améliorations ou des corrections qui concernent des commits déjà en cours de review.
Si ces Merge Request étaient mergés, cela ne me poserait pas de problème. Je proposerai de nouvelles Merge Request avec ces changements.
Dans la situation actuelle, si je souhaite effectuer une amélioration dans la Merge Request numéro 2, je préfère modifier directement cette Merge Request plutôt que d'en créer une nouvelle. Cette approche me semble plus logique et propre, surtout pour une Merge Request qui n'a pas encore été review.
En pratique, la modification de la Merge Request numéro 2 est une tâche fastidieuse. Si je modifie cette Merge Request, je vais devoir propager mon changement sur 6 branches et résoudre de nombreux conflits. J'ai peur de faire une erreur.
Cette opération est très pénible.
C'est pour cette raison que j'ai étudié dernièrement Stacked Git et Jujutsu.
Je me demande quel outil serait le plus adapté pour gérer ma problématique.
git-stack, git-branchless, Stacked Git ou Jujutsu 🤔.
Journal du mardi 29 avril 2025 à 22:36
Depuis un an que j'effectue des missions Freelance, j'ai régulièrement besoin d'effectuer des changements dans des projets pour intégrer mes pratiques development kit, telles que l'utilisation de Mise, .envrc, docker-compose.yml, un README guidé, etc.
Généralement, ces missions Freelance sont courtes et je ne suis pas missionné pour faire des propositions d'amélioration de l'environnements de développement.
En un an, j'ai été confronté à cette problématique à cinq reprises.
Jusqu'à présent, j'ai utilisé la méthode suivante :
- J'ai intégré mon development kit dans une branche
sklein-devkit - Cette branche m'a ensuite servi de base pour créer des branches destinées à traiter mes issues, nommées sous la forme
sklein-devkit-issue-xxx - Et pour finir, je transfère mes commits avec
git cherry-pickdans une branche du typeissue-xxxque je soumettais dans une Merge Request ou Pull Request.
À la base, ce workflow de développement n'est pas très agréable à utiliser, et devient particulièrement complexe lorsque je dois effectuer des git pull --rebase sur la branche sklein-devkit !
Dans les semaines à venir, pour le projet Albert Conversation, je dois trouver une solution élégante pour gérer un cas similaire. Il s'agit de maintenir des modifications (série de patchs) du projet https://github.com/open-webui/open-webui qui :
- seront soit intégrées au projet upstream après plusieurs semaines ou mois
- soit resteront spécifiques au projet Albert Conversation et ne seront jamais intégrées en upstream, comme par exemple l'intégration du Système de Design de l'État.
Je me souviens avoir été marqué par l'histoire du projet Real-Time Linux mentionnée dans l'épisode 118 du podcast de Clever Cloud : les développeurs de Real-Time Linux ont maintenu pendant 20 ans toute une série de patchs avant de finir par être intégrés dans le kernel upstream (source : la conférence "PREEMPT_RT over the years") !
Voici la liste des patchs maintenus par l'équipe Real-Time Linux :
└── patches
├── 0001-arm-Disable-jump-label-on-PREEMPT_RT.patch
├── 0001-ARM-vfp-Provide-vfp_state_hold-for-VFP-locking.patch
├── 0001-drm-i915-Use-preempt_disable-enable_rt-where-recomme.patch
├── 0001-hrtimer-Use-__raise_softirq_irqoff-to-raise-the-soft.patch
├── 0001-powerpc-Add-preempt-lazy-support.patch
├── 0001-sched-Add-TIF_NEED_RESCHED_LAZY-infrastructure.patch
├── 0002-ARM-vfp-Use-vfp_state_hold-in-vfp_sync_hwstate.patch
├── 0002-drm-i915-Don-t-disable-interrupts-on-PREEMPT_RT-duri.patch
├── 0002-locking-rt-Remove-one-__cond_lock-in-RT-s-spin_trylo.patch
├── 0002-powerpc-Large-user-copy-aware-of-full-rt-lazy-preemp.patch
├── 0002-sched-Add-Lazy-preemption-model.patch
├── 0002-timers-Use-__raise_softirq_irqoff-to-raise-the-softi.patch
├── 0002-tracing-Record-task-flag-NEED_RESCHED_LAZY.patch
├── 0003-ARM-vfp-Use-vfp_state_hold-in-vfp_support_entry.patch
├── 0003-drm-i915-Don-t-check-for-atomic-context-on-PREEMPT_R.patch
├── 0003-locking-rt-Add-sparse-annotation-for-RCU.patch
├── 0003-riscv-add-PREEMPT_LAZY-support.patch
├── 0003-sched-Enable-PREEMPT_DYNAMIC-for-PREEMPT_RT.patch
├── 0003-softirq-Use-a-dedicated-thread-for-timer-wakeups-on-.patch
├── 0004-ARM-vfp-Move-sending-signals-outside-of-vfp_state_ho.patch
├── 0004-drm-i915-Disable-tracing-points-on-PREEMPT_RT.patch
├── 0004-locking-rt-Annotate-unlock-followed-by-lock-for-spar.patch
├── 0004-sched-x86-Enable-Lazy-preemption.patch
├── 0005-drm-i915-gt-Use-spin_lock_irq-instead-of-local_irq_d.patch
├── 0005-sched-Add-laziest-preempt-model.patch
├── 0006-drm-i915-Drop-the-irqs_disabled-check.patch
├── 0007-drm-i915-guc-Consider-also-RCU-depth-in-busy-loop.patch
├── 0008-Revert-drm-i915-Depend-on-PREEMPT_RT.patch
├── 0053-serial-8250-Switch-to-nbcon-console.patch
├── 0054-serial-8250-Revert-drop-lockdep-annotation-from-seri.patch
├── Add_localversion_for_-RT_release.patch
├── ARM__Allow_to_enable_RT.patch
├── arm-Disable-FAST_GUP-on-PREEMPT_RT-if-HIGHPTE-is-als.patch
├── ARM__enable_irq_in_translation_section_permission_fault_handlers.patch
├── netfilter-nft_counter-Use-u64_stats_t-for-statistic.patch
├── POWERPC__Allow_to_enable_RT.patch
├── powerpc_kvm__Disable_in-kernel_MPIC_emulation_for_PREEMPT_RT.patch
├── powerpc_pseries_iommu__Use_a_locallock_instead_local_irq_save.patch
├── powerpc-pseries-Select-the-generic-memory-allocator.patch
├── powerpc_stackprotector__work_around_stack-guard_init_from_atomic.patch
├── powerpc__traps__Use_PREEMPT_RT.patch
├── riscv-add-PREEMPT_AUTO-support.patch
├── sched-Fixup-the-IS_ENABLED-check-for-PREEMPT_LAZY.patch
├── series
├── sysfs__Add__sys_kernel_realtime_entry.patch
└── tracing-Remove-TRACE_FLAG_IRQS_NOSUPPORT.patch
46 files
J'ai été impressionné, je me suis demandé comment cette équipe a réuissi à gérer ce projet aussi complexe sur une si longue durée sans finir par se perdre !
Real-Time Linux n'est pas le seul projet qui propose des versions patchées du kernel, c'est le cas aussi du projet Xen, Openvz, etc.
J'ai essayé de comprendre le workflow de développement de ces projets. Avec l'aide de Claude.ai, il semble que ces projets utilisent un outil comme quilt qui permet de gérer des séries de patchs.
Il semble aussi que Debian utilise quilt pour gérer des patchs ajoutés aux packages :
Quilt has been incorporated into dpkg, Debian's package manager, and is one of the standard source formats supported from the Debian "squeeze" release onwards.
J'ai creusé un peu de sujet et à l'aide de Claude.ai j'ai découvert des alternatives "modernes" à quilt.
- Git lui-même :
git format-patchpour créer des séries de patchesgit ampour appliquer des patchesgit range-diffpour comparer des séries de patches- Branches de fonctionnalités +
git rebase -ipour organiser les commits
- Stacked Git (https://stacked-git.github.io/) :
- Topgit (https://github.com/mackyle/topgit) :
- Gère des changements de code sous forme de piles (stacks)
- Permet de maintenir des patches à long terme pour des forks
- Git Patchwork - (https://github.com/getpatchwork/patchwork) :
- Système de gestion et suivi des patches envoyés par email
- Utilisé par le noyau Linux et d'autres projets open source
- Guilt (http://repo.or.cz/w/guilt.git) :
- Jujutsu :
- Système de contrôle de version moderne basé sur Git
- Meilleure gestion des branches et séries de patches
- Git Series (https://github.com/git-series/git-series) :
- Outil pour travailler avec des séries de patches Git
- Permet de suivre l'évolution des séries au fil du temps
Après avoir jeté un œil sur chacun de ces projets, j'envisage de créer un playground pour tester Stacked Git.
Divers types d'issues, une issue Vision ou Epic est floue, une issue task est précise
En mars 2024, je me suis demandé comment utiliser correctement les termes Epic, issue, User Story, Goal, Job Story, Vision, Pitch, Feature, Task, Bug, Spike, Dette technique, Theme.
Voici quelques réflexions à ce propos.
Tout d'abord, tous les artefacts suivants sont des Issues : Epic, User Story, Job Story, Vision, Pitch, Feature, Bug, Spike, Task.
Ensuite, Feature, Bug, Spike et Dette technique indiquent la finalité de l'issue, définissant la nature du travail à réaliser.
User Story et Job Story sont des méthodes de formulation d'issues.
J'ai mis beaucoup de temps à réaliser que les termes Epic, Vision, Theme, Pitch, Goal et Task permettent d'indiquer le niveau d'imprécision d'un objectif.
Exemple allant du flou très prononcé à une version faiblement floue :
- Vision – Le niveau le plus large et abstrait, décrivant une aspiration à long terme.
- Theme – Une direction stratégique regroupant plusieurs objectifs ou Epics.
- Pitch – Une proposition d'idée ou une justification d'un projet, pouvant inclure des objectifs mais restant plus conceptuel.
- Goal – Un objectif spécifique à atteindre, souvent mesurable.
- Epic – Une grande fonctionnalité ou un ensemble de tâches qui contribuent à un objectif plus large.
- Task – Niveau le plus précis, une tâche est une unité de travail concrète et actionnable.
Une ou plusieurs Merge Requests constituent une réponse formelle, exprimée en code, parmi toutes les réponses possibles à une demande formulée dans une issue.
Seule cette réponse formelle, exprimée en code, est véritablement précise. Même l'issue, aussi détaillée soit-elle, conserve toujours une part de flou.
Attention tout de même : quand je dis qu'une issue de type Vision est floue, cela ne veut pas dire que son auteur peut bâcler sa rédaction.
Si, par exemple, la description est limitée à 500 mots, l'auteur doit exploiter au mieux cette limite pour présenter sa vision avec précision. L'objectif n'est pas de créer du flou volontairement, mais plutôt d'exprimer clairement un concept qui, par nature, comporte encore des zones d'incertitude à explorer.
Voici quelques exemples d'issue floue publiés ici :
Une issue, en tant que texte écrit, comporte une part inévitable d'ambiguïté et nécessite donc son auteur pour être défendue :
C’est que l’écriture, Phèdre, a, tout comme la peinture, un grave inconvénient. Les œuvres picturales paraissent comme vivantes ; mais, si tu les interroges, elles gardent un vénérable silence. Il en est de même des discours écrits. Tu croirais certes qu’ils parlent comme des personnes sensées ; mais, si tu veux leur demander de t’expliquer ce qu’ils disent, ils te répondent toujours la même chose. Une fois écrit, tout discours roule de tous côtés ; il tombe aussi bien chez ceux qui le comprennent que chez ceux pour lesquels il est sans intérêt ; il ne sait point à qui il faut parler, ni avec qui il est bon de se taire. S’il se voit méprisé ou injustement injurié, il a toujours besoin du secours de son père, car il n’est pas par lui-même capable de se défendre ni de se secourir.
Conséquence pratique de tout cela :
- L'auteur d'une issue doit être disponible et accorder du temps à la personne qui va implémenter son issue.
- La personne qui implémente cette issue doit accepter l'imprécision de cette issue. En posant des questions, le développeur doit aider l'auteur à rendre cette issue plus précise.
- L'auteur de l'issue doit accepter de recevoir une implémentation qui ne correspond pas exactement à sa vision… et dans ce cas, il doit soit l'accepter ou accorder plus de temps à cette issue afin d'effectuer plusieurs itérations de correction de l'implémentation.
Ces règles pratiques sont aussi valables lorsqu'une issue est déclinée dans des issues avec un niveau de précision supérieur. Par exemple, lors de la rédaction d'issues de type Epic à partir d'une issue de type Vision.
« Permettre à l'auteur de défendre son texte » ne signifie pas exclusivement un dialogue oral. Ce dialogue peut s'effectuer :
- Par chat synchrone ;
- Par commentaire d'issue asynchrone ;
- Par visioconférence ;
- etc
Je pense que le niveau de précision d'une issue détermine le mode de communication à privilégier. Pour les issues de haut niveau d'abstraction — très floues (Vision, Theme, Pitch), la communication orale se révèle généralement plus efficace, car elle permet des échanges dynamiques et immédiats sur des concepts abstraits.
En revanche, pour les issues plus précises (Tasks, certaines Features), je privilégie une approche asynchrone avec des questions écrites détaillées. Cette méthode offre à l'auteur le temps nécessaire pour réfléchir et affiner sa rédaction. Je ne recours à la communication orale que lorsque des problèmes de compréhension persistent malgré les échanges écrits, afin de débloquer rapidement la situation.
Je cherche des solutions pour bien indiquer le niveau de précision des issues que j'écris.
Voici quelques exemples d'introductions d'issues :
Cette issue est de type "vision", c'est donc normal qu'elle soit imprécise. Les zones d'ombre seront affinées progressivement dans des sous-issues spécifiques. Pour clarifier certains aspects, des échanges oraux pourront être organisés afin de répondre à vos questions et d'enrichir cette vision.
Autre exemple :
Cette issue a été rédigée avec un souci particulier de précision. Si vous identifiez des erreurs, des incohérences ou si certains points nécessitent des éclaircissements, n'hésitez pas à les signaler dans les commentaires. Pour toute difficulté de compréhension ou doute persistant, je reste disponible pour organiser une session en visioconférence afin de faciliter nos échanges.
Journal du mardi 28 janvier 2025 à 13:49
Alexandre me dit : « Le contenu de Speed of Code Reviews (https://google.github.io/eng-practices/review/reviewer/speed.html) ressemble à ce dont tu faisais la promotion dans notre précédente équipe ».
En effet, après lecture, les recommandations de cette documentation font partie de ma doctrine d'artisan développeur.
Note: j'ai remplacé CL qui signifie Changelist par Merge Request.
When code reviews are slow, several things happen:
- The velocity of the team as a whole is decreased. Yes, the individual who doesn’t respond quickly to the review gets other work done. However, new features and bug fixes for the rest of the team are delayed by days, weeks, or months as each Merge Request waits for review and re-review.
- Developers start to protest the code review process. If a reviewer only responds every few days, but requests major changes to the Merge Request each time, that can be frustrating and difficult for developers. Often, this is expressed as complaints about how “strict” the reviewer is being. If the reviewer requests the same substantial changes (changes which really do improve code health), but responds quickly every time the developer makes an update, the complaints tend to disappear. Most complaints about the code review process are actually resolved by making the process faster.
- Code health can be impacted. When reviews are slow, there is increased pressure to allow developers to submit Merge Request that are not as good as they could be. Slow reviews also discourage code cleanups, refactorings, and further improvements to existing Merge Request.
J'ai fait le même constat et je trouve que cette section explique très bien les conséquences 👍️.
How Fast Should Code Reviews Be?
If you are not in the middle of a focused task, you should do a code review shortly after it comes in.
One business day is the maximum time it should take to respond to a code review request (i.e., first thing the next morning).
Following these guidelines means that a typical Merge Request should get multiple rounds of review (if needed) within a single day.
Je partage et recommande cette pratique 👍️.
If you are too busy to do a full review on a Merge Request when it comes in, you can still send a quick response that lets the developer know when you will get to it, suggest other reviewers who might be able to respond more quickly.
👍️
Large Merge Request
If somebody sends you a code review that is so large you’re not sure when you will be able to have time to review it, your typical response should be to ask the developer to split the Merge Request into several smaller Merge Requests that build on each other, instead of one huge Merge Request that has to be reviewed all at once. This is usually possible and very helpful to reviewers, even if it takes additional work from the developer.
Je partage très fortement cette recommandation et je pense que c'est celle que j'avais le plus de difficulté à faire accepter par les nouveaux développeurs.
Quand je code, j'essaie de garder à l'esprit que mon objectif est de faciliter au maximum le travail du reviewer plutôt que de chercher à minimiser mes propres efforts.
J'ai sans doute acquis cet état d'esprit du monde open source. En effet, l'un des principaux défis lors d'une contribution à un projet open source est de faire accepter son patch par le mainteneur. On comprend rapidement qu'un patch doit être simple à comprendre et rapide à intégrer pour maximiser ses chances d'acceptation.
Un bon patch doit remplir un objectif unique et ne contenir que les modifications strictement nécessaires pour l'atteindre.
Je suis convaincu que si une équipe de développeurs applique ces principes issus de l'open source dans leur contexte professionnel, leur efficacité collective s'en trouvera grandement améliorée.
Par ailleurs, une Merge Request de taille réduite présente plusieurs avantages concrets :
- elle est non seulement plus simple à rebase,
- mais elle a aussi plus de chances d'être mergée rapidement.
Cela permet à l'équipe de bénéficier plus rapidement des améliorations apportées, qu'il s'agisse de corrections de bugs ou de nouvelles fonctionnalités.
Journal du lundi 26 août 2024 à 15:09
Lorsque vous collaborez avec moi, je préfère recevoir les extraits de vos textes Markdown, vos codes sources, et le contenu de votre terminal au format texte plutôt que sous forme de captures d'écran.
Voici ci-dessous six inconvénients liés à l'utilisation de captures d'écran.
1. Impossibilité de copier le contenu
Lorsque vous partagez des lignes de commande, des configurations ou des messages d'erreur en capture d'écran, je ne peux pas copier le contenu pour le tester ou effectuer des recherches. Cela m'oblige à ressaisir manuellement le texte, avec le risque d'introduire des erreurs.
De plus, il m'est impossible de citer précisément une partie de votre contenu lors de nos échanges.
2. Impossible de cliquer sur les liens
3. Recherche inefficace
Les outils comme GitHub, GitLab, Slack, Zulip, Mattermost, Signal, WhatsApp, ainsi que les moteurs de recherche dans les pages des navigateurs, ne permettent pas de rechercher du texte présent dans des images. Le format texte, en revanche, est entièrement indexable et facilitera la recherche d'informations.
4. Consommation de mémoire multipliée par 100
Les captures écrans consomment beaucoup plus d'espace disque que du texte.
Prenons l'exemple d'un extrait de terminal au format texte :
# docker info
Client: Docker Engine - Community
Version: 27.1.2
Context: default
Debug Mode: false
Plugins:
buildx: Docker Buildx (Docker Inc.)
Version: v0.16.2
Path: /usr/libexec/docker/cli-plugins/docker-buildx
compose: Docker Compose (Docker Inc.)
Version: v2.29.1
Path: /usr/libexec/docker/cli-plugins/docker-compose
Server:
Containers: 194
Running: 194
Paused: 0
Stopped: 0
Images: 34
Server Version: 27.1.2
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Using metacopy: false
Native Overlay Diff: true
userxattr: false
Logging Driver: json-file
Cgroup Driver: systemd
Cgroup Version: 2
Cet extrait consomme 682 octets de mémoire.
Je viens de vérifier : une capture d'écran équivalente consomme 83 000 octets de mémoire, soit 121 fois plus d'espace disque qu'un simple extrait de texte. Pour ceux qui utilisent des écrans haute résolution, comme les écrans Retina, cette consommation peut même être multipliée par 4.
Il est regrettable de saturer 100 fois plus rapidement l'espace disque sur des services comme GitHub, GitLab, Slack, Zulip, Mattermost, etc., pour une expérience utilisateur finalement moins optimale.
5. Chargement moins rapide des pages
Ceci est surtout impactant pour les issues ou Merge Request avec beaucoup de commentaires.
6. Occupation excessive de l'espace écran
Les captures d'écran, en particulier celles prises sur des écrans Retina, occupent souvent un espace d'écran excessif dans la fenêtre du navigateur, rendant la lecture des commentaires plus difficile et nuisant à la fluidité de la navigation.
Journal du vendredi 23 août 2024 à 12:35
Depuis des années, j'essaie de suivre avec rigueur la doctrine suivante dans les projets utilisant le workflow Trunk-Based Development.
- La branche trunk doit toujours être stable et contenir uniquement du code fonctionnel.
- Le code obsolète ou inutilisé doit être supprimé de la branche trunk.
- Aucun code commenté ne doit figurer dans la branche trunk.
- La branche trunk ne contient pas de tests qui échouent.
Pourquoi ?
- Pour éviter qu'un développeur perde du temps à essayer de faire fonctionner quelque chose qui n'est pas en état de marche.
- Pour éviter qu'un développeur refactore du code mort — j'ai observé à nouveau cela, il n'y a pas longtemps 😔. Quand le développeur fini par le découvrir, il est généralement très frustré.
- Pour éviter l'installation et la mise à jour de bibliothèques qui alourdissent inutilement le projet.
- Pour prévenir une perte de confiance dans le projet (voir l'hypothèse de la vitre brisée).
Et si j'ai besoin de ce code plus tard ?
Tout d'abord, je vous réponds "YAGNI" 🙂.
Plus sérieusement, ma réponse est que votre code ne sera pas perdu étant donné qu'il est versionné dans votre repository.
Si le code commenté est en cours de développement, alors je suggère d'extraire ce code en préparation dans une Merge Request et de la merger quand elle sera prête.
Trouvez le bon équilibre
Un morceau de code commenté ou un test qui échouent peut tout à fait rester dans trunk sur une courte période. Dans ce cas, je conseille d'ajouter en commentaire un lien vers l'issue de dette technique qui détaille l'action prévue.
Journal du mercredi 21 août 2024 à 09:39
Après avoir rédigé la note Commit Cavalier, #JaiDécouvert le concept de des projets de loi omnibus.
« Depuis les années 1980, cependant, les projets de loi omnibus sont devenus plus courants : ces projets de loi contiennent des dispositions, parfois importantes, sur un éventail de domaines politiques. »
-- from
Ceci m'a fait penser aux Merge Requests qui contiennent de nombreux petits commits, souvent de refactoring, qu'il serait fastidieux de passer en revue individuellement.
Je pense que je vais nommer ces Merge Request, des Merge Request Omnibus, ce néologisme sera une de mes marques idiosyncrasiques 😉.
J'ai donc décidé de baptiser ces Merge Requests des Merge Requests Omnibus. Ce néologisme deviendra l'une de mes marques idiosyncrasiques 😉.
Journal du mardi 20 août 2024 à 23:26
Je tente ici de présenter la notion de Git Commit dit "cavalier" en la reliant au concept de Cavalier Législatif.
Un cavalier législatif est un article de loi qui introduit des dispositions qui n'ont rien à voir avec le sujet traité par le projet de loi.
Ces articles sont souvent utilisés afin de faire passer des dispositions législatives sans éveiller l'attention de ceux qui pourraient s'y opposer.
-- from
Dans le contexte de développement logiciel, un Commit Cavalier désigne un commit inséré dans une Pull Request ou Merge Request qui n’a aucun lien direct avec l’objectif principal de celle-ci.
Cette pratique pose les problèmes suivants :
- Cela rend la Merge Request plus difficile à review ;
- Cela rend la Merge Request plus longue à review ;
- Cela lance des discussions sans lien avec l'objectif de la Merge Request ;
- Le Commit Cavalier devient "invisible" au reste de l'équipe ;
- L'auteur peut mettre la pression au reviewer pour merger son Commit Cavalier sous prétexe que la Merge Request doit être mergé rapidement.
Il va sans dire que cette pratique a le don de m'irriter profondément. Par respect pour mon reviewer et mon équipe, je veille scrupuleusement à ne jamais soumettre de commit cavalier.
Journal du mardi 20 août 2024 à 18:05
Depuis 2012, je pratique exclusivement le Git Rebase Workflow pour tous mes projets de développement.
Concrètement :
- J'utilise
git pull --rebasequand je travaille dans une branche, généralement une Pull Request ou Merge Request ; - Je pousse régulièrement des commits en "work in progress" au fil de l'avancée de mon travail dans ma branche de développement avec la commande
git commit -m "WIP"; git push; - Une fois le travail terminé, je squash mes commits à l'aide de
git rebase -i HEAD~[NUMBER OF COMMITS]; - Ensuite, je rédige un commit message qui contient la description du changement et le numéro de l'issue ou de la merge request
git commit --amend; - Enfin, j'effectue un Merge en Fast-Forward en utilisant l'interface de GitHub ou GitLab.
Pour cela, je paramètre GitLab de la façon suivante (navigation "Settings" => "General") :

Ou alors je paramètre GitHub de la façon suivante (navigation "Settings" => "General")
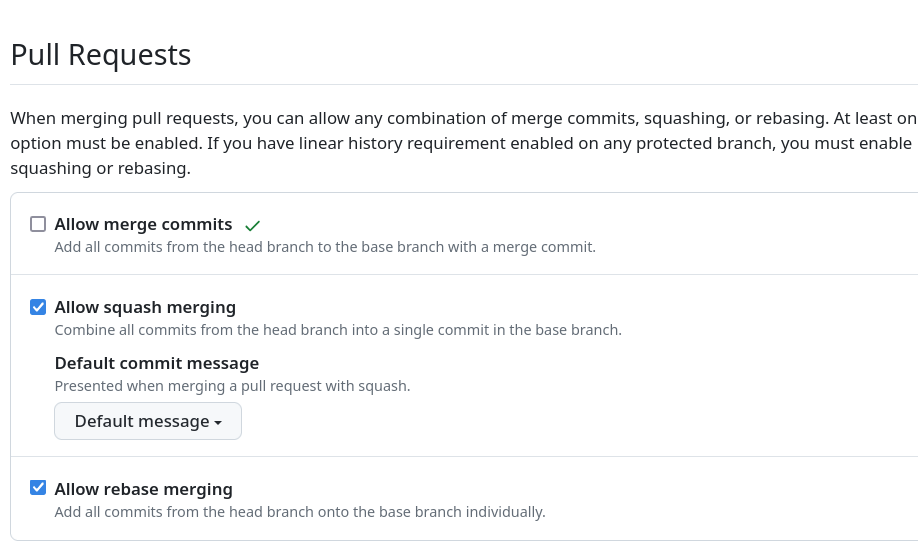
Les avantages de cette pratique
L'approche Rebase + Squash + Merge Fast-Forard permet de maintenir l'historique de changements linéaire, rendant celui-ci plus facile à lire et à comprendre.
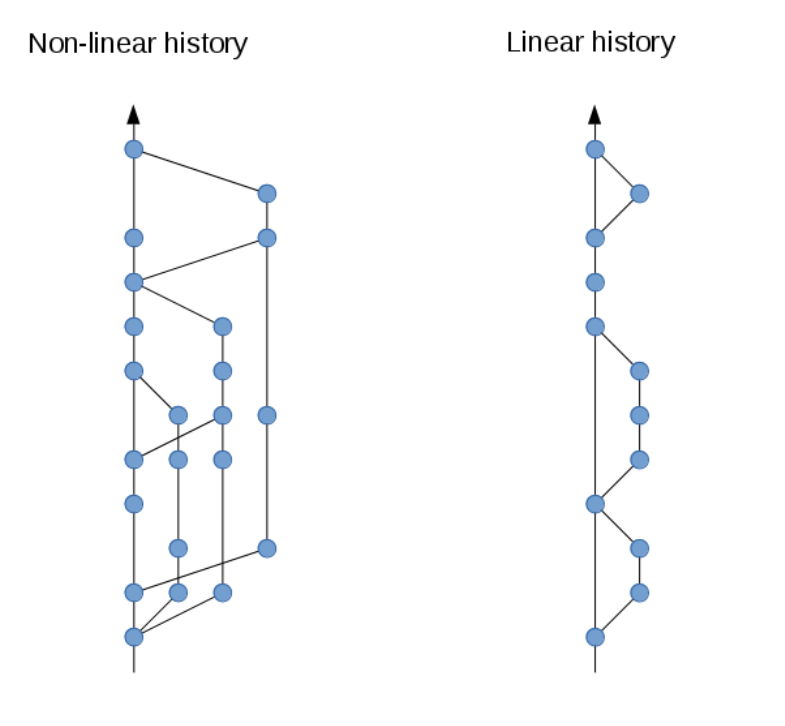
L'historique ne contient aucun commit de fusion inutile.
Cela facilite la mise en place d'Intégration Continue.
Tous les problèmes, bugs, et conflits sont traités dans les branches, dans les Merge Request et jamais dans la branche main qui se doit d'être toujours stable, ce qui améliore grandement le travail en équipe.
Ce workflow est particulièrement puissant lorsque l'historique linéaire ne contient que des commit dit "atomic", c’est-à-dire : 1 issue = 1 merge request = 1 commit. Un commit est considéré comme "atomic" lorsqu'il ne contient qu'un seul type de changement cohérent, tel qu'une correction de bug, un refactoring ou l'implémentation d'une seule fonctionnalité.
À de rares exceptions près, le code source de la branche main doit rester stable et cohérent tout au long de l'historique des commits.
Cette discipline favorise un travail collaboratif de qualité, rendant plus compréhensible l'évolution du projet.
De plus, l'atomicité des commits facilite la revue des Merge Request et permet d'éviter les Commits Cavaliers.
Généralement je couple ce Git workflow au workflow nommé Trunk-Based Development.